企业 AI 落地,
月均 ¥1,250 起,数据不出内网
SPARK 本地算力租赁 + One API 模型网关 + Hermes / OpenClaw Agent 部署 —— 从开箱到上线,励康一站式交付。
推理速度 3-5 倍于云 API
128GB 统一内存开箱即用
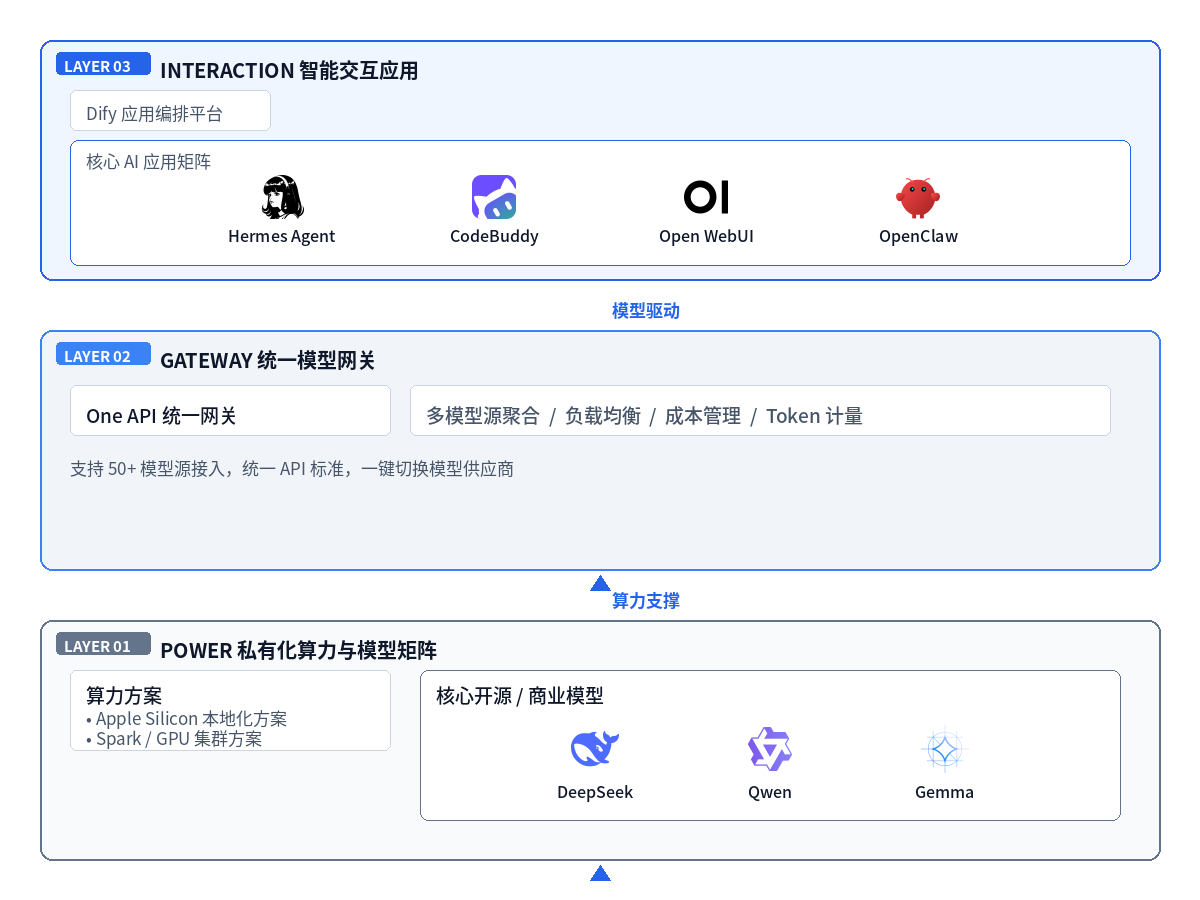
励康 AI Agent 全栈方案:从算力支撑到智能交互的闭环架构
核心方案
1. AMD 锐龙 AI Max+ 395 租赁方案 (性价比之选)
- 配置:128GB 统一内存 · RDNA 3.5 核显 · 高速 NVMe 存储
- 优势:性价比高,128GB 大内存跑 70B 模型,功耗低
2. SPARK 算力盒子租赁方案 (推荐 · CUDA 生态)
- 配置:128GB 统一内存 + 1TB 高速存储 · 可级联至 256GB · 2 PFLOP
- 优势:CUDA 生态兼容,推理速度快 3-5 倍,开箱即用,高隐私
3. GPU 集群方案
- 硬件:NVIDIA A100/H100 GPU 集群
- 优势:支持 70B+ 参数模型,弹性扩展
- 适用:大型企业 AI 中台建设
励康的服务
One API 统一网关
解决多模型源导致的代码重复、成本失控、风险集中等问题。
核心能力:
- 支持 50+ 模型源(OpenAI、Claude、文心、DeepSeek 等)
- 统一 API 调用接口,自动故障转移
- 实时成本统计与配额管理
- API Key 集中管理,请求审计
- 请求缓存与负载均衡
励康的服务 (另行计费)
核心方案
1. Dify:AI 应用编排平台
- 拖拽式工作流编排,无需代码
- 知识库集成,支持文档、PDF、网页
- Agent 框架,支持工具调用
- 版本管理与 A/B 测试
2. Hermes:AI 交互体验框架
- 流式输出优化,逐字显示
- 多轮对话管理,上下文维护
- 富文本渲染(Markdown、代码、表格)
- 移动端完美适配
励康的服务 (另行计费)

GB10 vs AMD 395:中小企业本地AI算力怎么选?
NVIDIA GB10 Grace Blackwell 与 AMD Ryzen AI Max+ 395 两大路线正面交锋。从实测推理速度、CUDA 生态到价格门槛,帮您找到最匹配业务场景的本地算力方案。
企业知识库 QA 机器人
上传企业文档、制度、技术文档等,员工通过自然语言提问,AI 自动从文档中查找答案。
效率提升 80%客服机器人
自动处理 70% 的常见问题,复杂问题转接人工。7×24 小时可用,大幅降低客服成本。
成本降低 50%内容生成助手
输入关键信息,AI 自动生成多个版本的营销文案、技术文档等。支持 A/B 测试快速验证。
效率提升 5-10 倍代码审查助手
开发者提交代码前,AI 自动进行初筛,检查安全漏洞、性能问题、代码规范等。
审查效率提升 30%数据分析助手
业务人员上传 CSV/Excel,用自然语言提问。AI 自动生成分析代码、图表、报告。
分析周期缩短至分钟级工作流自动化
AI 自动调用企业系统 API(CRM、ERP、财务系统等),完成数据查询、处理、更新。
效率提升 5-10 倍DGX Spark vs Mac mini M4 Pro
基于 LMSYS 的权威评测数据,我们的算力方案在主流大模型(如 DeepSeek-R1, Qwen-32B, Llama-3.1)的推理速度上表现卓越。
- 本地化推理优势:在 Batch=1 的场景下,Mac mini M4 Pro 展现了极高的性价比与响应速度。
- 集群扩展能力:DGX Spark 在处理超大规模模型(如 70B+)及高并发任务时具备更强的吞吐性能。
- 全场景覆盖:无论是单机本地运行还是企业级集群部署,励康均能提供最优的能效比方案。
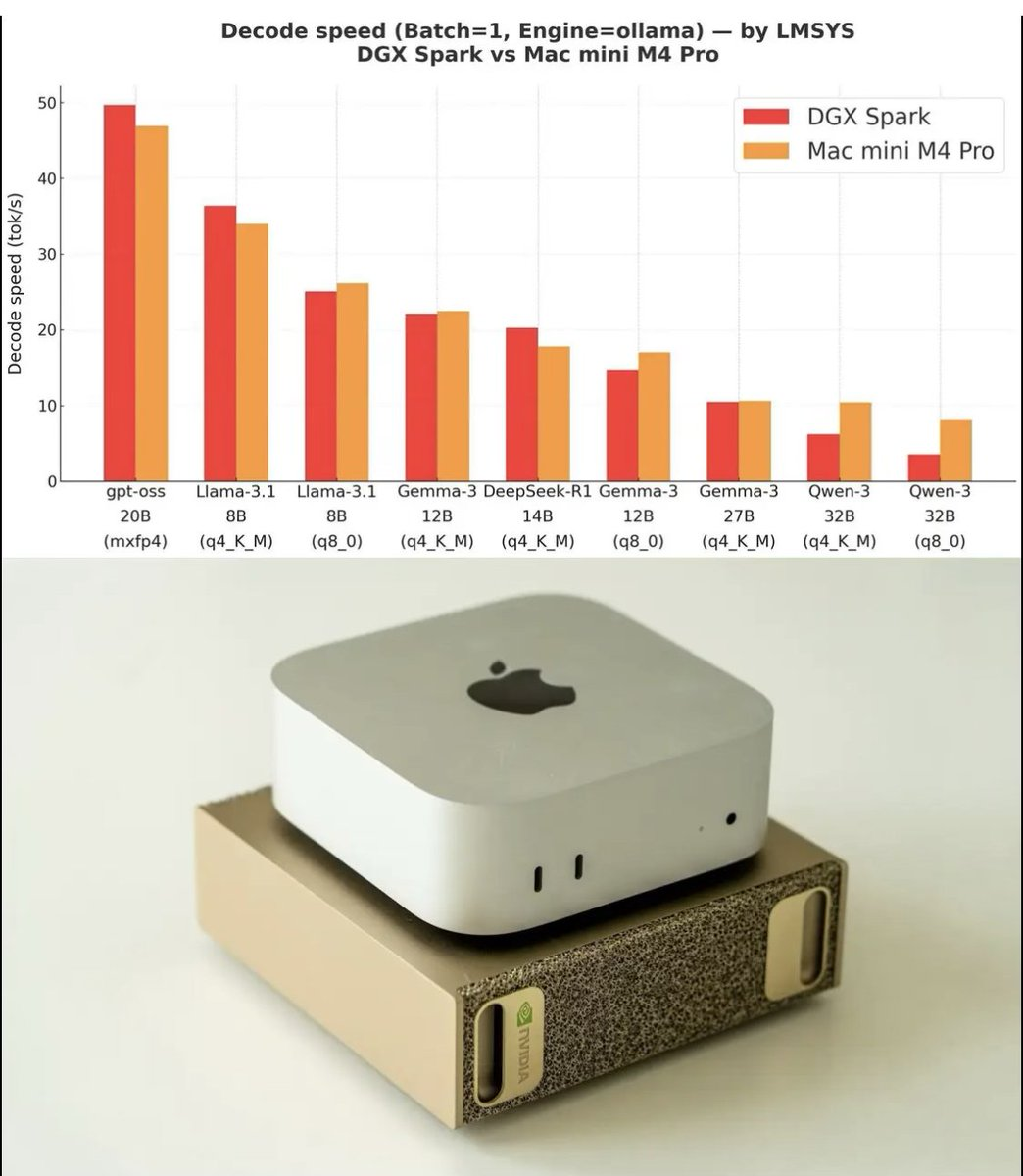
数据来源:LMSYS (Decode Speed, Engine=ollama)
一站式服务
从底层算力到顶层应用,全部由我们负责。您只需告诉我们业务需求。
本地化支持
广州本地技术服务商,上门现场支持,快速响应问题。
成本透明
帮您选择最经济方案,优化使用成本,拒绝账单黑盒。
数据安全
数据完全留在企业内部,满足等保二级及以上合规要求。
灵活扩展
从小规模试点到大规模部署平滑扩展,逐步扩大应用范围。
免费部署一个 AI Agent,
或做一次 IT 全面体检
珠三角企业专属——您可以选免费部署一个 Hermes 或 OpenClaw Agent 到您的环境,零成本体验 AI 价值;也可以选免费 IT 体检,专家上门评估基础架构。先体验,再决定。